たった3000のデータで当選した伝説の大統領
2016年の米大統領選挙はヒラリー・クリントンとトランプの一騎討ちで、多くの世論調査では「クリントン有利」としていたのに、予想は外れました。このときの選挙以上に有名なのが1936年のアメリカの大統領選挙でしょう。

本丸諒『グラフとクイズで見えなかった世界が見えてくる すごい統計学』(飛鳥新社)
この年は、民主党はルーズベルト候補(現職大統領)、共和党はランドン候補の対決でしたが、無名のギャラップ社(当時の名称はアメリカ世論研究所)は、全米の有権者から3000人の調査で「ルーズベルトが54%で有利」と予想。
これに対し、世論調査で定評のあったリテラリー・ダイジェスト社(以下、ダイジェスト社)は「ランドン57%で勝利」を予想。そのサンプル数は実に200万人で、ギャラップ社の700倍。
その結果はどうだったか……? 46州でルーズベルトが勝ち、選挙人獲得数はルーズベルト523人に対し、ランドンはわずか8人だったのです。ここで問題です!
なぜ、200万人ものサンプルを集めたダイジェスト社が予想を外し、たった3000人のサンプルでギャラップ社は的中できたのでしょうか?
200万のビッグデータが負けた本当の理由
答えは、「ダイジェスト社は、サンプリングのミスをした」です。
予想を大きく外したダイジェスト社の場合、自社の雑誌購読者(高額な雑誌)、電話やクルマの保有者の総計1000万人を選び、そのなかから200万人の回答を得ていました。
当時、電話やクルマを所有できる人は高所得層に限られており、多くは共和党支持者でした。つまり、200万人のサンプルを集めたといっても、ほとんど同じ階層、同じ政党支持者の人々からの回答を得ていたのです。
対するギャラップ社は、都市の男女、農村の男女という地域別・性別、あるいは富裕層、それに次ぐ層などの所得別など、人口比にできるだけ等しく抽出していました。
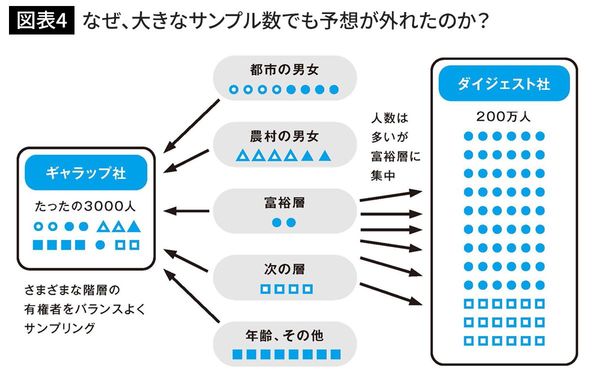
つまり、「投票者の縮図」を作成し、それに合わせて回答を得ていたのです。結果的に、正しい縮図をつくれば、小さなサンプルでも全体を反映できることがわかったのです。





