
※本稿は、遠藤正之『金融DX、銀行は生き残れるのか』(光文社新書)の一部を再編集したものです。

連続障害を引き起こした5つの問題点
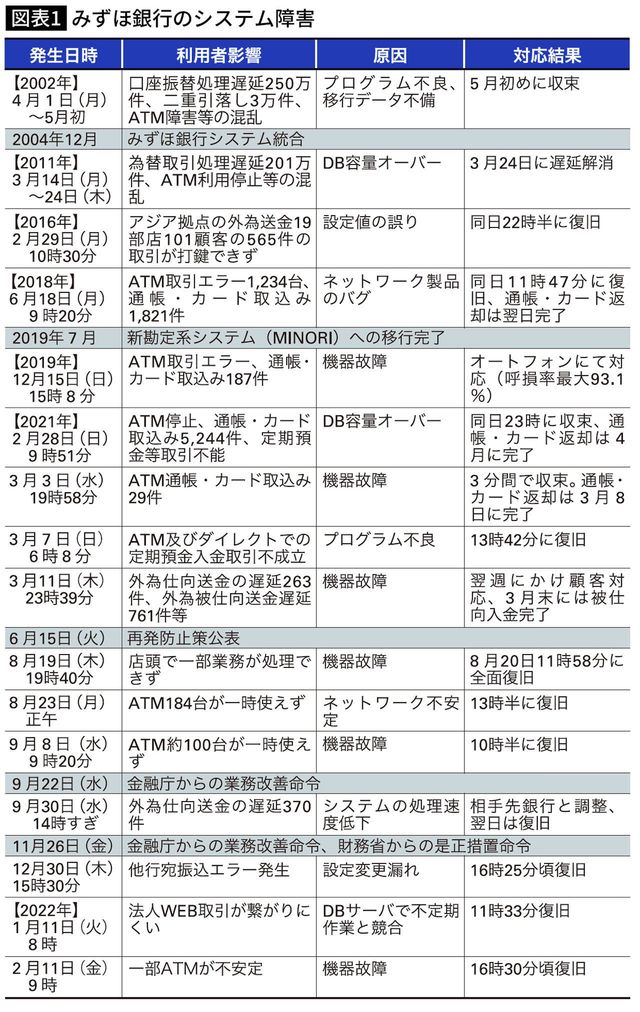
みずほ銀行の連続障害の原因を掘り下げていくと、次の五点に集約できるのではないかと考えられる。
第一に、MINORIのアーキテクチャの複雑性、第二に、保守運用フェーズでのリソース削減が急であったこと、第三に、経営とIT現場とのコミュニケーションが不十分だったこと、第四に、システム関連の銀行組織、開発会社、運用会社が連携しにくい体制であること、第五に、機器の所有を各ベンダーとしたことが挙げられる。順に見ていこう。
大規模システムでは、マルチベンダー(多数のITベンダー企業が開発を分担すること)となることは不可避である。マルチベンダー自体は問題ではない。むしろ勘定系システムの本体部分が、四つの異なる基盤システムで構成されている点が問題である(図表2)。
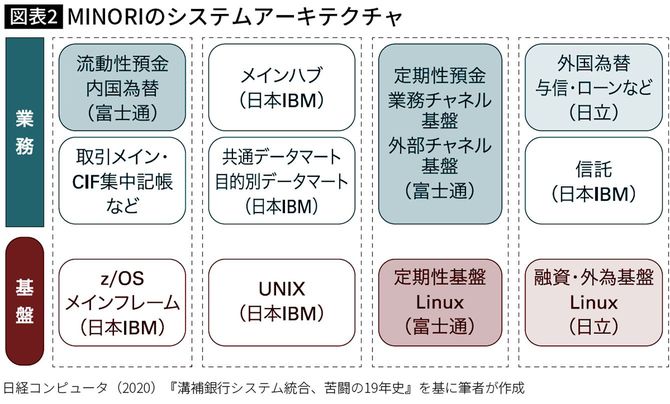
それぞれのOS(Operating System、基本ソフトウェア)も異なり、データベース管理システムも異なっている。それぞれの専門家はいても、その相違点を十分に理解できる専門家はほぼいないのではないかと考えられる。
障害はなぜ「リリースから2年後」に起きたのか
基盤をまたぐ障害に対応するためには両方の専門家が参画する必要があるが、そうなると対応するスピードはどうしても遅くなってしまう。特に社内にスキルの高い専門家が常駐していればいいが、そうでない場合、対応スピードはさらに落ちてしまう。第二の原因によるリソース削減で、スキルの高い専門家は常駐していなかったと推測される。
大型プロジェクトの場合、リリース直後に障害が発生する。みずほ銀行のシステムリリースは実質的に2019年2月だった。それから約2年たって、システム障害が発生したことに着目すべきである。有識者である各ベンダーの専門家をそれまでは引き留めていたが、リソース削減策の中で引き留めができなくなり、十分な引き継ぎもできず、障害の予兆管理能力や発生後の対応力が低下したと考えられる。




