「生成AIは著作権侵害」と提訴が相次ぐ
今後ChatGPTの利用を維持・拡大するための課題は、日米とも「回答の精度」が5割弱を占めています(図表4)。
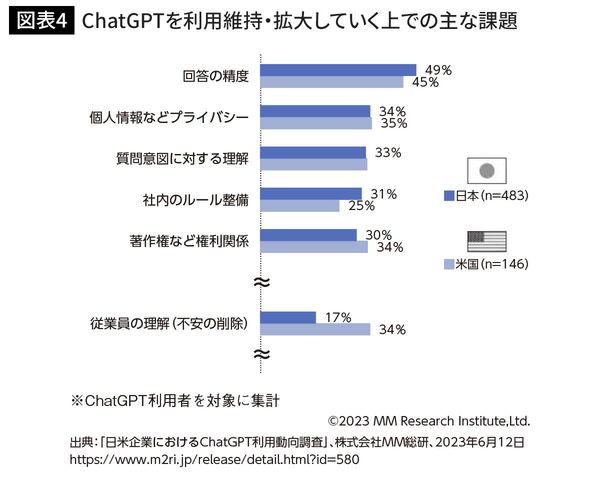
また「著作権などの権利関係」にも大きな関心が集まっています。
ChatGPTをはじめ生成AIは、ウェブ上の膨大なデータを機械学習することによって開発されました。これらのデータは著作権者に無断で使われているケースが多いため、既にOpenAIなどIT企業と新聞社などコンテンツ・ホルダー間で摩擦が生じ始めています。
2023年1月には、米国でイラストレーターやマンガ家らがミッドジャーニー等の画像生成AIを提供する業者らを相手取って集団訴訟を起こしました。また同年6月には、同じく米国でChatGPTを提供するOpenAIに対し、一般消費者から集団訴訟が起こされました。いずれも著作権侵害を起訴理由としています。
今後はこれら裁判の行方などが生成AIの普及に大きな影響を与えそうです。
日本の「ChatGPT後進国」ぶりは問題なのか
ここまで見てきたように、ChatGPTの職場への導入については日米の間で大きな開きが生じています。ただ、「日本が米国に遅れをとっているのは問題だ」と決めつけるのは早計かもしれません。
ChatGPTのような生成AIはときに誤った情報や「幻覚」と呼ばれる「でっち上げ」等の回答を返してきます。また、それらの回答(テキストや画像などのコンテンツ)が第三者の著作権を侵害している可能性もあります。
これらを考慮するなら、ChatGPTの導入に日本企業の多くが若干及び腰になるのも、ある程度理解できます。
また、一旦導入した後も、その活用に際しては慎重かつ思慮深い姿勢が求められます。かつてグーグルで「LaMDA」など大規模言語モデルの評価作業を担当していたAI研究者のマーガレット・ミッチェル氏は次のように語っています。
「生成AIは貴方(ビジネスパーソン)が知らないことを知るためのツールではありません。むしろ貴方が既にできることを、さらによくできるようにするためのツールなのです」
これはどういう意味でしょうか?




