教師AIが生徒AIを学習させる「蒸留」
学習というのは、AIのなかにある定数を調整することを意味します。この調整には膨大な計算が必要で、定数の数も、規模が大きいものでは数千億個といった膨大なものになります。
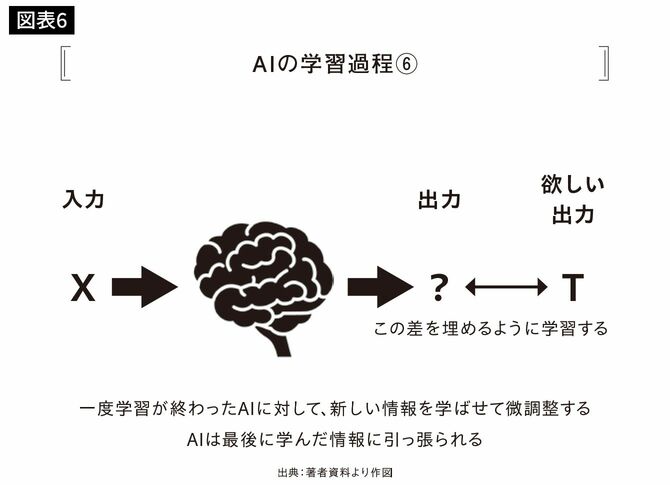
また、一度学習したAIに対して、新しいデータセットで微調整をかける学習を行うことができます。これをファインチューニングと言います。
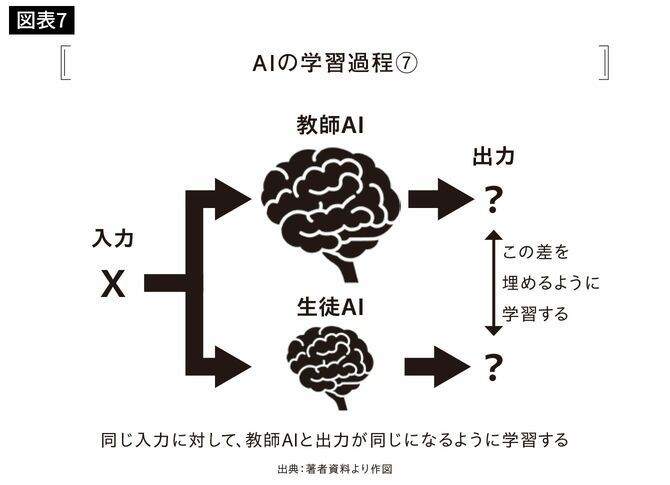
さらに、大規模で高性能なモデルを教師AIとして、小規模なモデルを生徒AIとして学習させることを「蒸留(distillation)」と言います。
ChatGPTのコスト問題も解決に向かっている
AIは蒸留しても性能がほとんど落ちないことがよく知られています。

清水亮『検索から生成へ 生成AIによるパラダイムシフトの行方』(MdN)
実は、扱おうとする問題に対して、AIの規模(パラメータ数)が多すぎるかもしれない、という状態はよくあります。
「GPT-3」のような大規模言語モデルは学習データに対して規模が大きすぎないか確証がないまま1750億という超巨大なモデルを学習させました。そのために数百億円の機材と数億円の電気代、一日7000万円とも言われる維持費が必要になりました。
しかし、GPT-3も蒸留すればもっと小さなモデルで同等以上の性能が出せる可能性を指摘され、実際にいくつもそうしたモデルが現れ始めています。





