システムの窮状がトップまで届いていなかった
経営者とシステム開発の現場のリスク感覚に関する意思疎通ができていなかったことも、大きな原因と考えられる。システム部門の総責任者をCIO(Chief Information Officer)という。CIOは本来、経営トップの方針をシステム部門に伝えることと、システム部門の状況を経営トップに伝える双方向の役割がある。
しかしながら、2019年4月にみずほのCIOに就任した人物は人事や企画畑が長く、システムには精通していない人物だった。そのため、経営トップの方針をシステム部門に伝える役割だけが機能して、システム部門の視点での適切な進言を経営トップにすることができなかったと考えられる。その結果、システム部門の感覚では、リスクが高まるレベルまで人員やベンダーの要員を削減してしまったのではないか。
2021年6月に公表されたシステム障害調査報告書でも、3ページ(114ページから116ページ)にわたって、アンケート調査やホットラインで受け取った意見がまとめてあり、そのことが裏付けられる。
組織系統が複雑で大きなエラーに対処しきれない
みずほ内部が、みずほ銀行と開発会社の二層構造になっている点や、開発会社(みずほリサーチ&テクノロジーズ)と運用会社(MIデジタルサービス)の資本関係が異なる点等、組織的に複雑で、スムーズな連携を阻害している(図表3)。
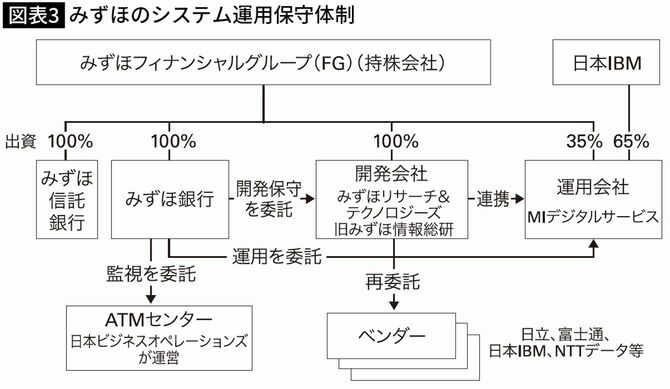
またIT関連会社の再編により、保守体制が弱まった可能性がある。一つは、2020年6月に日本IBMの資本を入れた運用会社MIデジタルサービスを設立した再編である。もう一つは、2021年2月から3月にかけて4件の障害が起きたにもかかわらず、2021年4月にシステム開発を行ってきたみずほ情報総研が、リサーチ会社であるみずほ総合研究所と合併し、みずほリサーチ&テクノロジーズを設立した再編である。
さらに、障害発生時の運用会社でのエラーメッセージの検知体制や、運用会社から開発会社への伝達方法が、印刷したうえで電話での口頭の連絡によるなど、アナログ的な手法であったことで、大量のエラーが発生した場合の対応が不十分になる素地があった。




