

※本稿は、古川渉一、酒井麻里子『先読み! IT×ビジネス講座 ChatGPT 対話型AIが生み出す未来』(インプレス)の一部を再編集したものです。

生成したテキストが犯罪に使われてしまう可能性は?
【酒井】ChatGPTはどんなテキストでも生成できるからこそ、悪い目的で使われてしまう可能性もありそうです。悪用のリスクについては、どのように考えればいいのでしょうか? たとえばChatGPTで、犯罪を助長するような内容の文章が生成されてしまう可能性はないんでしょうか?
【古川】基本的に、犯罪につながるような内容は生成できないように制限がかけられています。たとえば「爆弾の作り方」のような質問をしても、「それは答えられません」のような返答になるはずです。
【酒井】では、問題ないと考えて大丈夫でしょうか?
【古川】いえいえ、そうとは限らないですよ。たとえば、「小説の設定を考えています」のような前置きをすることで回答を引き出せる可能性はありますし、抜け道はいくらでもあると思います。
【酒井】「あくまでも作り話である」という前提を与えてしまうんですね。
【古川】直接犯罪を匂わせるような内容ではない場合は、さらに難しいと思います。たとえば、ChatGPTに「ラブレターの文面を考えて」と指示して作った文章が、異性を装って相手に近づく詐欺に悪用されるケースもあるかもしれません。
【酒井】本当にラブレターを書いている可能性もあるので、はじくのは難しいでしょうね。実在企業を装ったフィッシングメールなども同じように生成できてしまいそうです。
フィッシングメールやマルウェアのコードも生成可能
【古川】それだけではなく、マルウェアのプログラミングコードを生成できてしまうのではという指摘もありますよ。
【酒井】悪用したいと考える人は、いくらでもその方法を考えるでしょうからね。
【古川】普及していくにつれて、悪い使われ方もされるようになってしまうのは技術の宿命だと思っています。それを踏まえて、利用する側とサービス提供者側の双方の倫理が求められています。
【酒井】ユーザーとしてはそういった使い方をしない、サービス提供者側は悪用できないしくみや、悪用するユーザーを検出できる環境をできるだけ整えるという感じでしょうか?
【古川】そうですね。たとえば、包丁を使った殺人事件が起きたからといって、包丁を規制するのは現実的ではないですよね。それと同じだと思います。
【酒井】どんな道具でも悪いことに使われてしまう可能性はあるので、それを踏まえて倫理観を持って使うことが大切ということですね。
差別を助長する文章が生成されてしまう可能性も
【酒井】ChatGPTなどの文章生成AIが、差別的な表現を含んだ文章を生成してしまう可能性もあるのでしょうか?
【古川】その可能性は排除しきれません。実際、Microsoftが2016年に発表した対話型AIの「Tay」は、Twitter上でユーザーとやりとりしながら学習するものでしたが、公開されて間もなく差別的な発言を繰り返すようになり、すぐに公開停止に追い込まれました。
【酒井】悪意をもったユーザーが意図的に差別的な価値観を学習させたことが原因ではないかといわれていますよね。
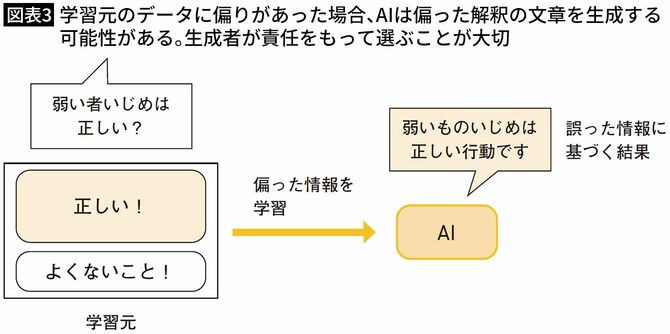
【古川】AIは「事実」を答えることは得意ですが、それに対する「解釈」は学習データに依存する部分が大きいんです。偏った解釈を多く学習していれば、その結果が生成されてしまう可能性もあるんです。
【酒井】偏った解釈に基づいた文章が生成される可能性を理解したうえで、生成されたものを使うかどうかは、文章を生成した人自身が責任をもって取捨選択する必要があるということですね。
【古川】そうですね。「AIが自分で考えて書いたものではない」という点はしっかり理解しておく必要があります。
社会の価値観を反映させるには最適化が必要
【酒井】明らかな差別発言や問題発言ではないものの、今の社会では問題視されやすい内容はどうでしょうか? たとえば、生活用品のキャッチコピー案を作ったときに、「家事は女性がするもの」という前提に立ったものが出てしまう可能性はありますか?
【古川】時代によって価値観の変わるものへの対応ということですね。この場合、ChatGPTでは生成される可能性はあると思います。
【酒井】「価値観」レベルのものは難しいということでしょうか?
【古川】そうですね。さらにいえば、ChatGPTはグローバルに展開されているサービスなので、国や地域によって価値観の違うものに対応するのも難しいと思います。
【酒井】そのあたりを、社会の価値観に合わせて調整することはできないんですか?
【古川】AIモデルそのものを新しく作ったり、AIのモデルに対してファインチューニングという形で調整したりするのが現実的でしょうね。今後、現代の日本文化により最適化された対話型AIが作られる可能性はあるかもしれませんよ。
「何が差別か」ということは人間が手作業で教えている
【酒井】やや別の方向性の話になるかもしれませんが、ChatGPTでは、強化学習のプロセスで、人間がよいか悪いかのスコア付けをするということでしたよね。これは、人間が差別表現などを除外しているということですか?
【古川】そうなんです。ところが、OpenAIがこの作業を行う人たちを低賃金で雇っていたことを問題視する声もあがっています。
【酒井】差別的な言葉や、暴力的な描写のあるテキストを読まなければならないのは苦痛な作業ですね。差別を防ぐための作業を差別的な低賃金で行わせていることも問題に感じます。現時点では、人の手を加えないと、不適切な表現を完全に排除することは難しいということでしょうか?
【古川】そうですね。それは今のAIの限界といえる部分かもしれません。「何が差別なのか」をコンピューターだけで学習することは難しいので、人の手で学習させる必要があるということですね。
【酒井】そもそもの前提として、AIが学習元次第で差別的な内容を生成してしまう可能性があることを理解しておくのがまず大切ですね。そして、明確な差別とはいえない価値観レベルの問題は、それぞれの文化に合わせて最適化したモデルを作るといった対応で解決できる可能性があること、「何が差別なのか」をAIに学習されるプロセスでは、人の手が加わっている現実があることも知っておく必要がありますね。
生成したテキストで権利侵害が問題になることはあるか
【酒井】生成AIを利用するにあたって、やはり気になるのが知らないうちに他人の権利を侵害してしまうリスクです。ChatGPTで生成した文章が、学習元のデータとまったく同じになってしまう可能性もゼロではないとのことでしたが、そっくりの文章だけではなく、「テイストの似た文章」が生成される可能性もありますか?
【古川】学習元のデータと似たテイストのものがAIで生成されてしまう問題は、画像生成AIでも議論になっていますね。
【酒井】学習元となった絵を描いた人からしたら、いい気分はしないですよね。文章生成AIで同じような問題が起きる可能性はないですか?
既存の文章に類似したものがないかの確認は必須
【古川】文章の場合、画像に比べると学習元の個人のテイストのようなものが生成結果に反映されにくい傾向はあると思いますよ。
【酒井】絵の場合、ひと目で「○○さんの絵だ!」とわかる画風などの特徴がありますが、文章の場合はピンポイントで「これは○○さんの文章」と個人を判別できる特徴は現れにくいということですね。
【古川】そうですね。とはいえ、問題が発生する可能性はゼロではないので、生成された文章を使う場合には、既存の文章に類似したものがないかの確認は必須になります。
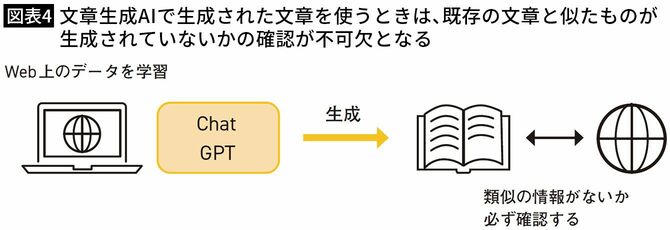
【酒井】ChatGPTで生成した文章を確認のためにWeb検索した結果、“微妙に似ている文章”が既存のサイトで見つかったとしても、「そっくりではないから権利侵害にはならない」と考えてそのまま使う人もいそうです。
AIだけでなく人間の頭脳も常に誰かの考えに影響される
【古川】そういった問題については、AIで生成したものでも、人間が書いたものでも同じかもしれませんよ。
【酒井】どういうことですか?
【古川】人間が文章を書くときも、その意見や考え方が完全に自分で思いついたものか、それとも本で読んだり誰かに聞いたりしたことの受け売りなのか、はっきりわからないケースは多いと思います。
【酒井】そうですね。“自分が考えていることの元ネタ”なんて、正確に把握しきれないことのほうが多いかもしれません。
【古川】自分のアウトプットが誰かの考えに影響されること自体は、日常で普通に起こっていることだと思います。だからこそ、自分のアイデアが既存のものに似ていないかの確認が必要になります。
【酒井】「世の中に出す前に類似のものがないかを確認する」という作業は、AI生成物だから特別に行うことではないということですね。
プログラミングコードの権利問題はより慎重に考える
【酒井】そのほかに、権利問題で知っておくべきことはありますか?
【古川】ChatGPTではプログラミングのコードの生成も可能ですが、こちらは文章に比べて問題が起きやすいのではないかといわれています。プログラムコードの生成に特化したAIサービスでは、集団訴訟も起きています。
【酒井】たとえば、少し珍しいコードの書き方をするエンジニアがいたとして、それを学習した場合に「その人しか書かないはずのコード」がChatGPTで生成されてしまう、という感じでしょうか?

【古川】そうですね。もちろん、「自分が書いたコードにそっくりなもの」がAIで生成されたからといって、必ずしも「そのコードをそのまま出した」とは言い切れません。
【酒井】確認のしようがないからという意味でしょうか?
【古川】そうですね。ブラックボックスの問題ですが、AIが学習元のデータのどの部分をどう利用しているのかといった部分はわからないので、何ともいえないんですよね。
【酒井】プログラミングコードを生成する場合は、文章の場合より慎重にチェックする必要がありそうですね。そして、文章生成の場合も、権利侵害が問題になる可能性はゼロではないので、生成された文章に類似したものがないかの確認は怠ってはいけないということがわかりました。
